Here at Physical Audio we’re just preparing to launch new, updated versions of our instrument and reverb plugins. They have been rewritten in the JUCE framework to give multi-platform output. As part of the relaunch we need to test the plugins on Apple’s new hardware, the M1 processor, as found in the new Mac mini. In this post we’ll look at the performance of this processor using our Plate Reverb algorithm, testing Intel builds of an audio plugin, the Rosetta 2 translation, and also Universal builds.

Back in 2016 we created an innovative algorithm design for plate reverberation. This uses physical modelling synthesis to produce the vibrations of a thin metal plate in real-time. Details of the algorithm can be found in this technical paper which we published at the International Congress on Acoustics. Others have tried to copy this, but the system requires mode optimisation to perform efficiently. We do this with our Physical Audio Optimisation Engine, the details of which are not published. Whilst the setup code for these algorithms uses some complex physics, the actual engine is very straightforward. We update the modal state of the plate using the state from the previous timestep, and the one before that, along with arrays of coefficients. Then there’s a sum reduction with weights to retrieve the output signal. These kind of operations come up a lot in audio processing, and so make a good test case for judging the performance of the new M1 processor and comparing it to recent Intel Macs.
So, lets take a closer look at the algorithm for the engine of the plate reverb. At each timestep we perform the following operations:
We then do a pointer swap so the state array q1 becomes q2, and q becomes q1. All very straightforward, but the size of the arrays for the purpose of this testing will be 6,000 elements. Now the first FOR loop requires 30,000 floating point operations and the second does 24,000, so for every second of audio at 44.1kHz we’re doing over 2 billion ops. That’s quite a lot of processing! To get any kind of reasonable CPU efficiency we’re going to need to be using vector units.

Although we do use multi-threading for some aspects of our code, the main weapon of choice for maximising performance on the audio thread is SIMD (Single Instruction Multiple Data). For Intel machines, this means using SSE or AVX instructions in the floating-point pipeline. AVX uses 256 bit wide vectors whilst the older SSE uses 128 bit vectors. The new M1 processor also uses 128 bit NEON vectors, and so for the purposes of this testing we will focus on using SSE instructions for the Intel builds (also Rosetta can’t handle AVX instructions). Now a 128 bit vector can hold 4 single-precision floats, so there are big performance gains to be found by computing additions and multiplications using these vectors. As both of the FOR loops in our algorithm have a similar number of floating-point operations, we will need to ensure that vector units are used for both of the loops. So, how do we go about doing this?
There are 3 ways to get these vector instructions in your binary (excluding linking to a library). The first is to manually write them in Assembly language, which we’re not going to look at here! The second is to get the compiler to do it for you, which we definitely will be looking at. Finally there are C++ vector intrinsics, and we’ll be making use of them in this example. To get the compiler to try to auto-vectorize we can simply turn on some level of -O optimisation. In order to see what the clang compiler is doing we can use the -Rpass=loop-vectorize flag. This will tell us which FOR loops have been vectorized, and the width of the vector that was used. When we apply -O3 optimisation to our plate reverb code we find that the first FOR loop is fully vectorized with either SSE or NEON instructions. However, the second FOR loop that computes the sum reduction is not vectorized. Not all optimisation is aggressive enough to do this, so let’s see how to use vector intrinsics instead.
So in both the SSE and NEON versions we are calculating 4 partial sums at each iteration of the FOR loop, and skipping over hops of 4 with the loop counter. We then simply sum together the results at the end. For reference, the JUCE framework has some wrappers for both the SSE and NEON intrinsics but we’re using the full code here so we can see exactly what’s going on. Now that we have fully vectorized code, it’s time for some testing.
For this initial stage of testing we’ll be using a late 2013 Mac Pro which has an Ivy Bridge 6-core Xeon E5, a 2017 Macbook Pro which has a Kaby Lake dual-core i7, and the new Mac Mini with it’s 8-core M1. To test as an audio plugin, we built a minimal Audio Unit v2 component with no UI features. We’re using the latest version of the JUCE 6 framework, compiling x86_64 builds on the Mac Pro and then a Universal build on the Mac mini to test native ARM64 performance.

To measure performance, we’re using Activity Monitor which shows the percentage of a CPU core (or virtual core for Intel Hyper-Threading) being used by a process. When using Logic Pro on Intel machines the Audio Unit v2 plugins show up in the Logic process itself, so we measure the difference between a single audio track during playback and the same track with the plugin loaded. On the M1 Mac mini these plugins run in a separate process, the AUHostingService for ARM64 versions or the AUHostingCompatibilityService for Intel builds running through Rosetta, so we just measure the CPU usage of that. We also double-check these figures using the audio thread CPU meter in AULab, Apple’s Audio Unit testing host. Here’s what we get.

So, this is a bit surprising for basic single-threaded performance. Our shiny new Mac mini performs slightly worse than our rather plain 13” MBP from a few years ago, and does not get close to the Xeon in the Mac Pro. The second surprising feature is the performance of the Rosetta 2 translation. We get exactly the same performance from the Intel build running on the Mac mini as we do from the native ARM64 build. The Rosetta system works very well indeed.
Audio plugins don’t exist in isolation, so let’s do a further test in Logic that examines the overall multi-core performance of the processors. On an otherwise idle machine, we will open an empty session in Logic and load a piece of audio on a stereo track. Then we’ll load our plate reverb plugin as an insert on that track and press Play to render some sound. Next, take another piece of audio and load it on a new audio track and load another instance of the plate reverb as an insert. Then press Play and render sound for a while. We’ll repeat this process, adding new tracks and inserts until Logic throws up a message saying it’s running out of resources. Logic will spread the load of the Audio Processing Graph across all available cores, so this is a good test of real-world CPU performance. For this testing we’ll just use the ARM64 build on the Mac mini, and we’ll also test on another machine, a top-spec 2016 15” MBP which has a Skylake 4-core i7.
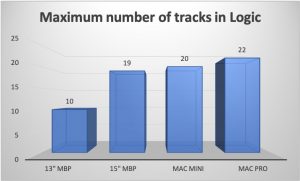
Now we’re seeing quite different results. The M1 processor performs as well as the i7 in our very expensive 15” MBP, and has double the performance of the low-power i7 in the 13” MBP. It’s almost as good as the 6-core Xeon in our Mac Pro (although that processor is pretty old now).
So, what have we learnt from all of this? Well, it depends on one’s perspective. For running an individual audio plugin, the new M1 processor has quite mediocre performance that barely keeps up with a 13” MBP from several years ago. That’s a bit disappointing. However for real-world usage in a Logic Pro session the new M1 performs much better, as good as a top-spec 15” MBP and almost as good as our old Mac Pro trash can. Considering that the later machines cost $3,000 each when new, the $700 Mac mini looks very good value for money. Probably the most surprising aspect is the performance of Rosetta 2. The translated Intel binaries performed as well as the native ARM64 builds, with no discernible difference in performance. Overall, we’re reasonably impressed with the M1 as a low-power chip. It should be very interesting to see what Apple comes out with for higher-power desktop versions over the next couple of years.